字符串基本处理操作的尝试
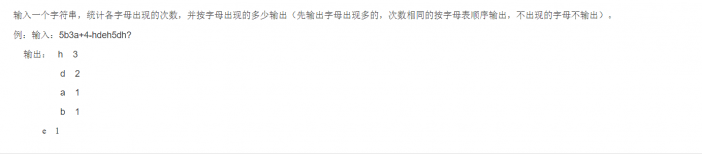
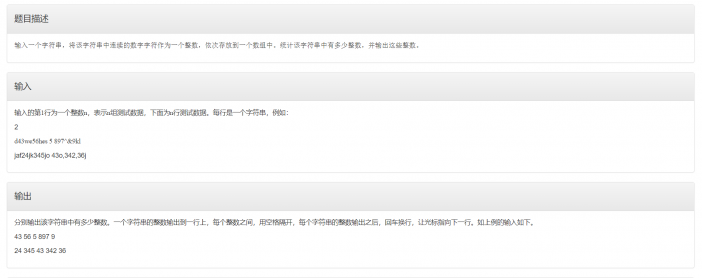
这两道编程题显然都是围绕的字符串的处理,这也意味着题目的核心就在于如何选取正确的方式对字符串进行处理。
这里我想说下我的基本思路。
由于编程采取的是模块化设计遵循“自顶向下,逐步细化“的基本准则。因此在进行编程题时我们要对代码块整体入手。例如这两道题起步代码块都是输入字符串,终止部分都是输出字符串。这两部分的代码就不用多说,但是我建议在输入部分采取的是
gets(字符串名);与此同时这两道题的中间代码块便是对字符串部分的操作
因此我们代码块整体思路是: 输入字符串——>处理字符串——>输出处理后的字符串
头部尾部的代码因人而异,我们就说下中间部分的。
图A总体思路:
由题意易得我们首要就是剔除数字 的干扰,然后便是对字母 进行查询判断以及计数,然后排序。
有了大致算法与思路接着便是对变量的设置,为了方便,我设置了两个一维数组,一个二维数组
尽管我二维数组是int但是由于C中整型和字符型可以通用最后的区别也只是占位符是%d和%c的区别。
char a[81], b[81]; //a接收初输入的字符串 b接收进行数字剔除后的字符串
static int c[2][26]; //使初始值为0方便后面输入break跳出循环 &c[0]用于存储字母类型 &c[1]用于存储字母对应的计数
而在加粗关键词中大家很容易联系到其中几个的算法。
如排序,很显然目前我们学的用的最多的就是冒泡排序和选择排序,因此我们直接套用即可。
剔除/过滤数字部分我采取如下代码:
//i用于控制a字符串的下标 j用于控制b字符串的下标
for (i = 0; i < strlen(a); i++) {
if (a[i] >= 'a' && a[i] <= 'z' || a[i] >= 'A' && a[i] <= 'Z') {
b[j++] = a[i]; //为何不直接b[i]=a[i]应该是显然易见的。
}
}
b[j]='\0'; //给b加结束符方便后续判断
n = j; //n用于记录b字符串的长度 为什么不用strlen(b)后面就知道了!
j = 0; //j归0后续再用
接下来就到了核心部分也即难点:如何分离出字母种类并且计数?
在不考虑算法所消耗的时间时,暴力使用26个switch来判断26个字母,好像是最简单的,但是这样就很无趣了。
我是采取使用两层嵌套for循环来解决这个问题。
第一层循环是用来遍历b字符串/数组 相当于查找字母种类
第二层循环是用来计数各字母种类
虽然大致这样说大家都懂但是还是感觉怪怪的,就比如说我怎么才能避免重复查找字母a呢?
例如我输入abacd,如果计算a字母的个数,按上述思路,第一层循环匹配到了开头的a字母,然后进入第二层循环查找a字母 于是乎我a字母个数便是2,但是我们第一层循环还是会再次匹配到字符串中下标为2的a,然后再进入第二层循环发现还是匹配到的a字母个数还是2,于是总数便是2+2=4,显然这样是错误的,但是我又怎么样才能避免重复计数和查找呢,这就很伤脑筋了。
那么我是这样解决的:
(如果计算a字母的个数,按上述思路,第一层循环匹配到了开头的a字母,然后进入第二层循环查找a字母 于是乎我a字母个数便是2)当这过程结束,我便将字符串中剩余的a字母全部变成空字符'\0'这样再加个if(xxx!= '\0')即可绕过并只进行了一次a字母种类的查询和一次a字母的计数。
具体实现如下:
//这里不用strlen(b)就是因为我后面会更改中间字母为'\0'从而使得strlen语法判断的字符长度变化
for (i = 0; i <n; i++) {
if (b[i] != '\0') { //这就是上面讲的解决思路
c[0][j] = b[i]; //二维数组c的第一行用于存储种类
for (t = 0; t < n; t++) {
if (b[t] == c[0][j]) {
c[1][j]++;
b[t] = '\0'; //这样做使得字符串后面的相同字母不会再次被查到
}
}
j++; //跳到下个字母种类
}
}
n = j; //记录二维数组第一行存储的字母种类的个数 也即第一行的串长
解决完查找和计数,后面就是对排序的套用,代码如下:
我这里用的是冒泡排序
第一次for循环是把个数大的往前排,使得最后降序输出。
第二次for循环是为了实现题目所述条件个数相同按字母表顺序排列
//rank
for (i = 0; i < n; i++) {
for (j = 0; j < n - i; j++) {
if (c[1][j + 1] > c[1][j]) { //第二行是 字母个数
t = c[1][j]; c[1][j] = c[1][j + 1]; c[1][j + 1] = t;
t = c[0][j]; c[0][j] = c[0][j + 1]; c[0][j + 1] = t;
//二维数组上下两行同时交换
}
}
}
for (i = 0; i < n; i++) {
for (j = 0; j < n - i; j++) {
if (c[1][j + 1] == c[1][j]) {
if (c[0][j + 1] < c[0][j]) { //第一行是 字母,然后利用ASCII码判断
t = c[0][j]; c[0][j] = c[0][j + 1]; c[0][j + 1] = t;
/ //由于个数相同,交换字母形式即可
}
}
}
}
到这里题目A基本就结束了我们看看结果
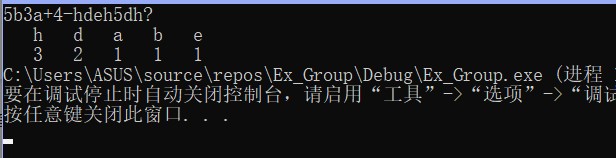
现在放出整体代码:
#include <stdio.h>
#include <string.h>
int main() {
char a[81], b[81];
int i, j=0,t,n;
static int c[2][26];
//input string
gets(a);
//filter string
for (i = 0; i < strlen(a); i++) {
if (a[i] >= 'a' && a[i] <= 'z' || a[i] >= 'A' && a[i] <= 'Z') {
b[j++] = a[i];
}
}
b[j]='\0';
n = j;
j = 0;
//search letter
for (i = 0; i <n; i++) {
if (b[i] != '\0') {
c[0][j] = b[i];
for (t = 0; t < n; t++) {
if (b[t] == c[0][j]) {
c[1][j]++;
b[t] = '\0';
}
}
j++;
}
}
n = j;
//rank
for (i = 0; i < n; i++) {
for (j = 0; j < n - i; j++) {
if (c[1][j + 1] > c[1][j]) {
t = c[1][j]; c[1][j] = c[1][j + 1]; c[1][j + 1] = t;
t = c[0][j]; c[0][j] = c[0][j + 1]; c[0][j + 1] = t;
}
}
}
for (i = 0; i < n; i++) {
for (j = 0; j < n - i; j++) {
if (c[1][j + 1] == c[1][j]) {
if (c[0][j + 1] < c[0][j]) {
t = c[0][j]; c[0][j] = c[0][j + 1]; c[0][j + 1] = t;
}
}
}
}
//output
for (i = 0; i < 26; i++) {
if (c[0][i] == 0) break;
printf("%4c", c[0][i]);
}
printf("\n");
for (j = 0; j < i; j++) {
printf("%4d", c[1][j]);
}
}
题目A讲解与个人思路就结束了
题目B的讲解与思路后续补进 咕咕咕
